❓ Is Test-Time Scaling as Effective as You Think?
(a) Sequential test-time scaling.
(b) Parallel test-time scaling.
Relative performance change across domains from the Baseline (B) specialized agent setting to the general agent (G) setting with unified context and tools. Negative values indicate performance degradation under the General AgentBench.
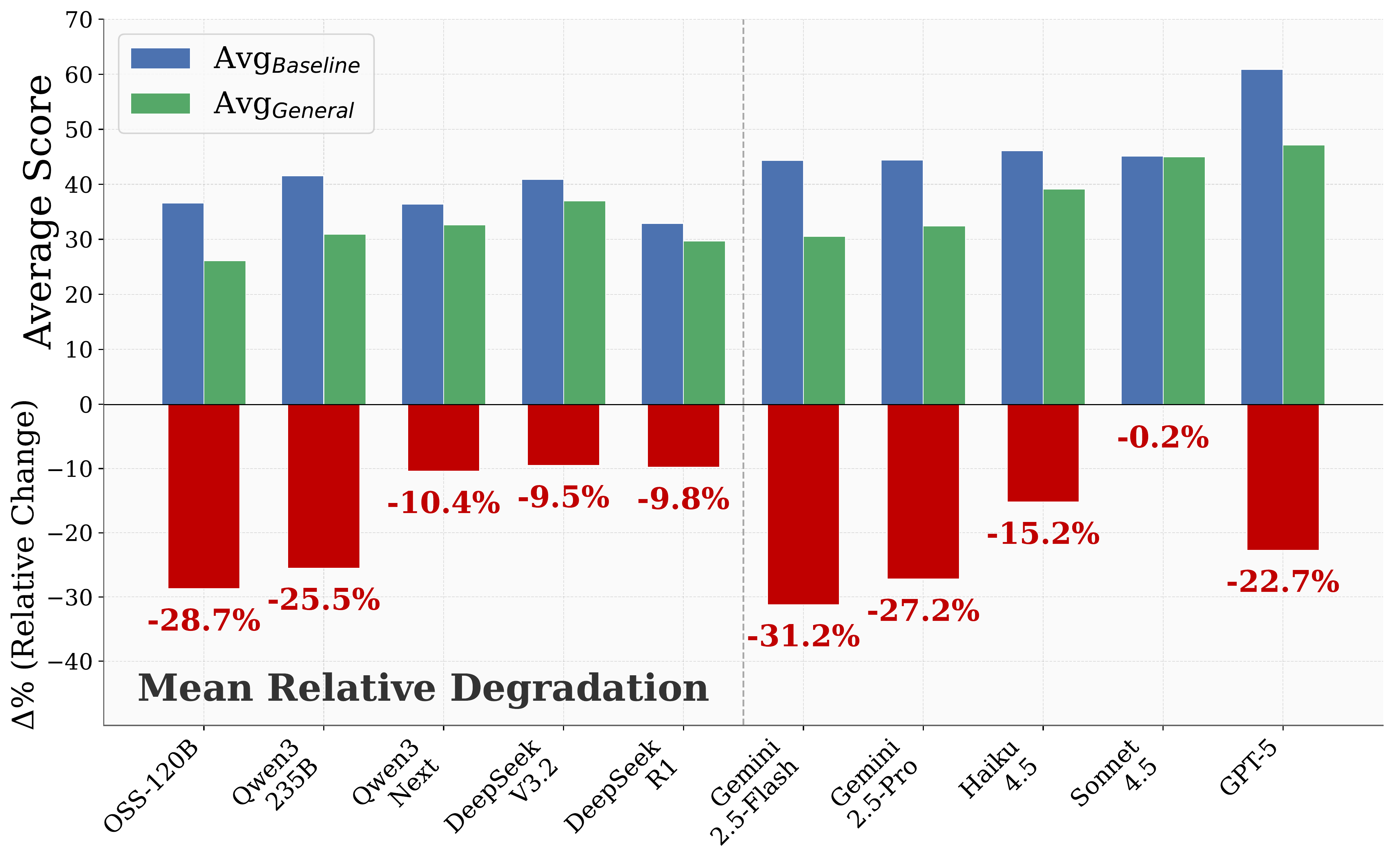
Performance comparison between specialized-agent and general-agent settings across models.
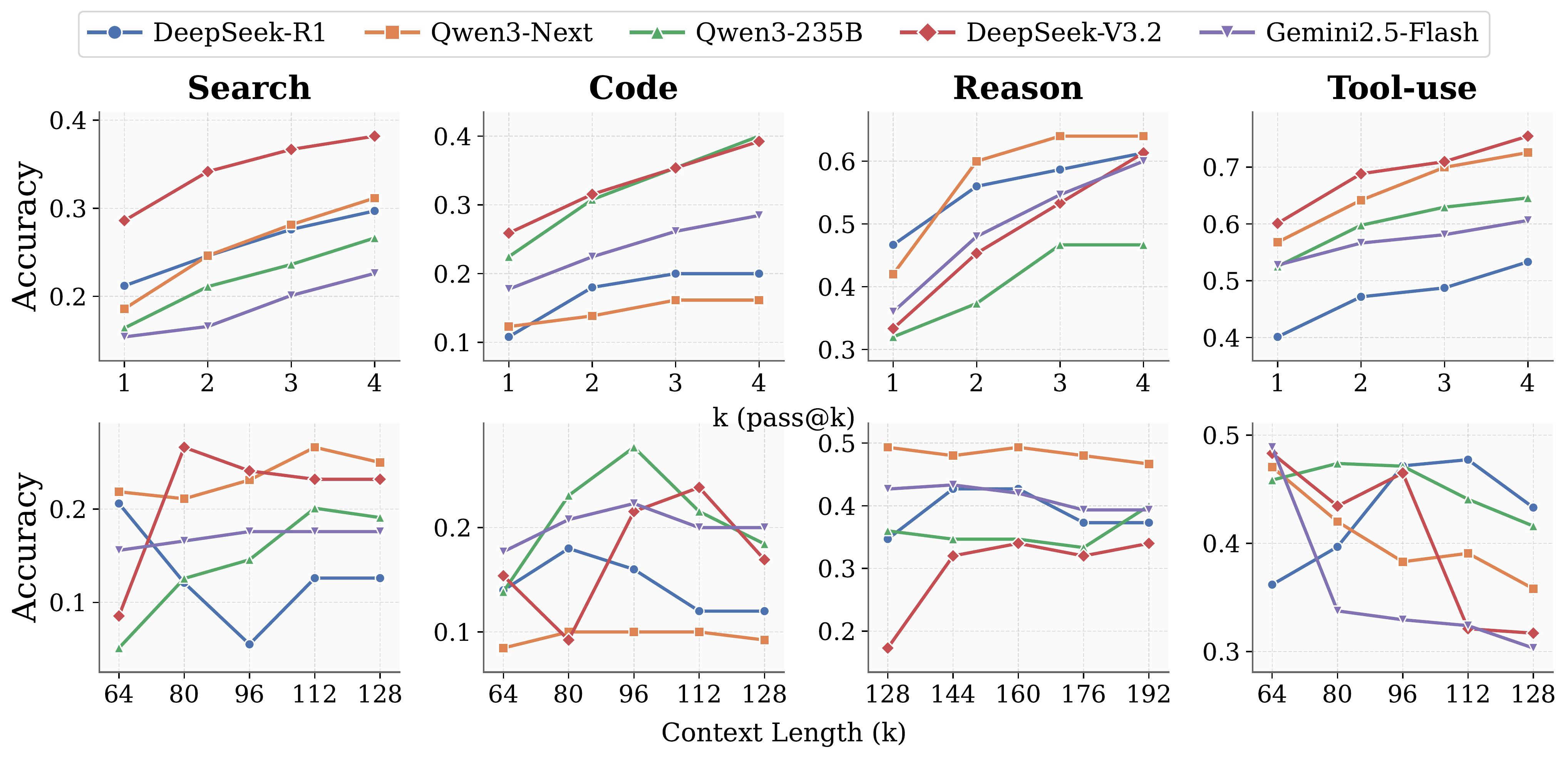
Test-time scaling behaviors of general LLM agents. Top: Parallel scaling expands the solution space through increased sampling. Bottom: Sequential scaling allocates additional computation via longer interaction histories, yet exhibits unstable or diminishing returns.
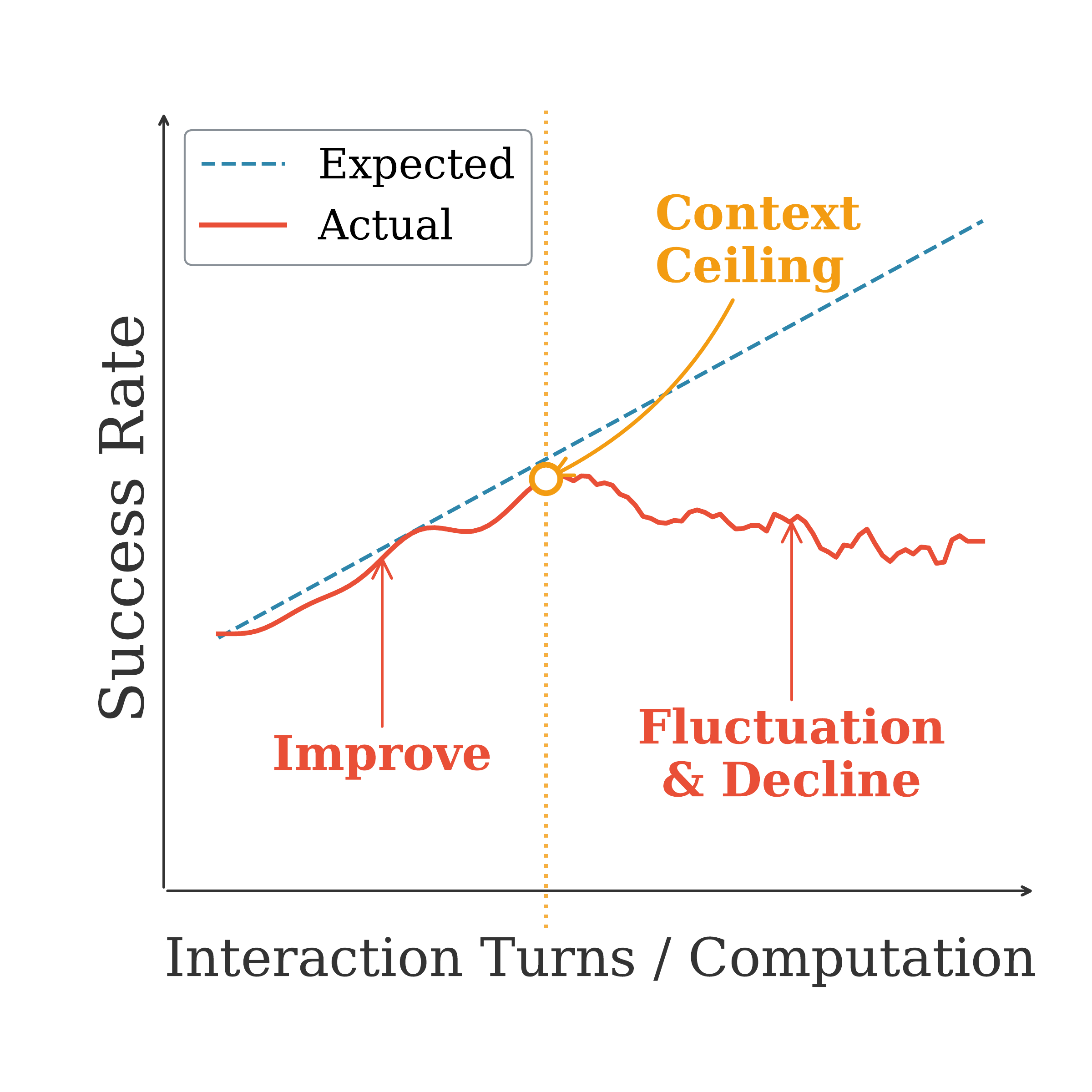
Sequential scaling extends the interaction horizon by injecting additional rounds of feedback. While performance initially improves as agents approach their inherent context length, it plateaus or degrades once context exceeds a critical threshold.
This context ceiling varies by model and domain—for example, approximately 112K tokens for Qwen3-235B and 96K for Gemini 2.5-Flash in the search domain. Beyond it, accumulated history overwhelms the agent's reasoning capacity, leading to instability in long-horizon tasks.
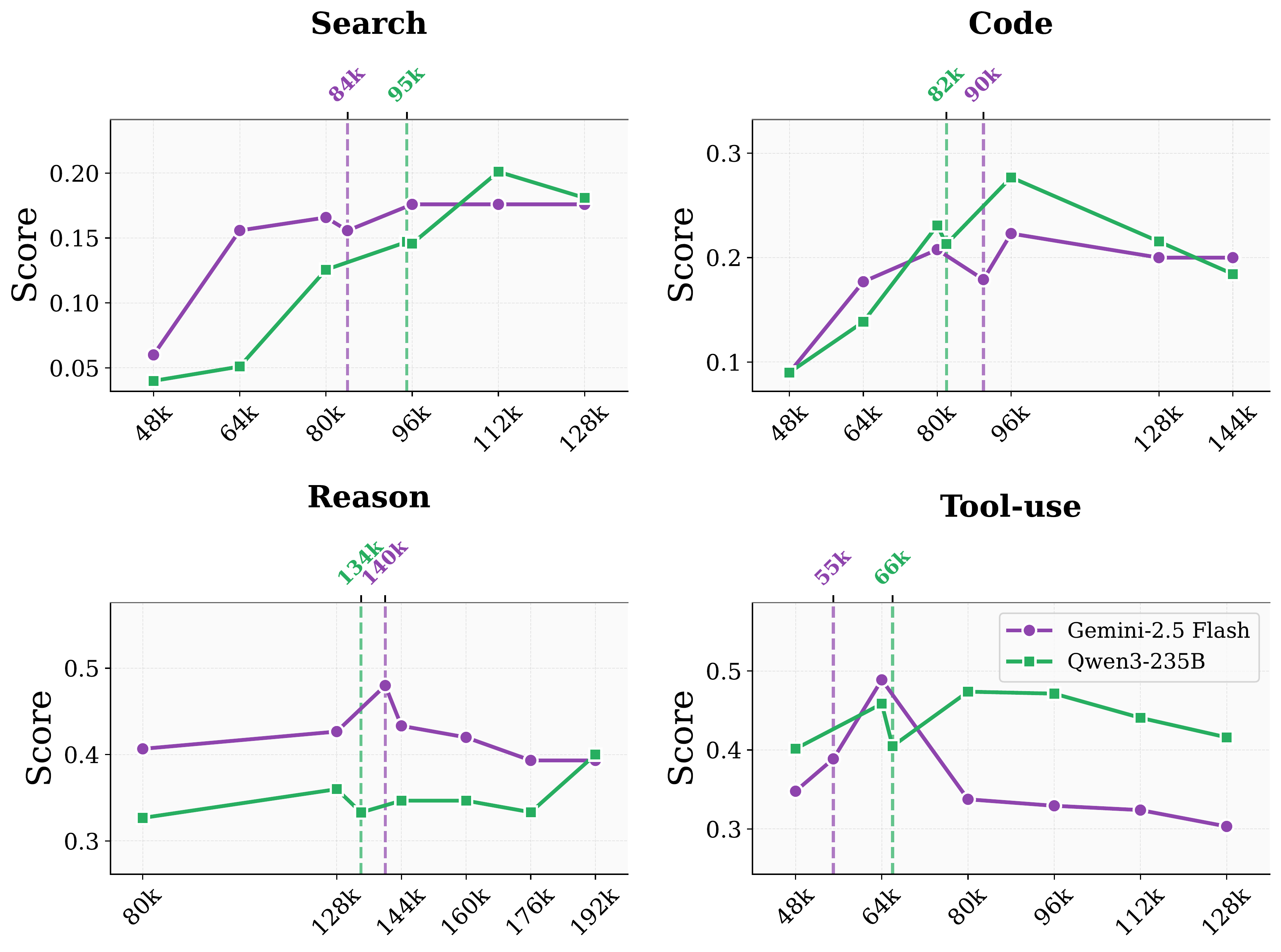
Sequential scaling behavior of Gemini 2.5-Flash and Qwen3-235B across domains.
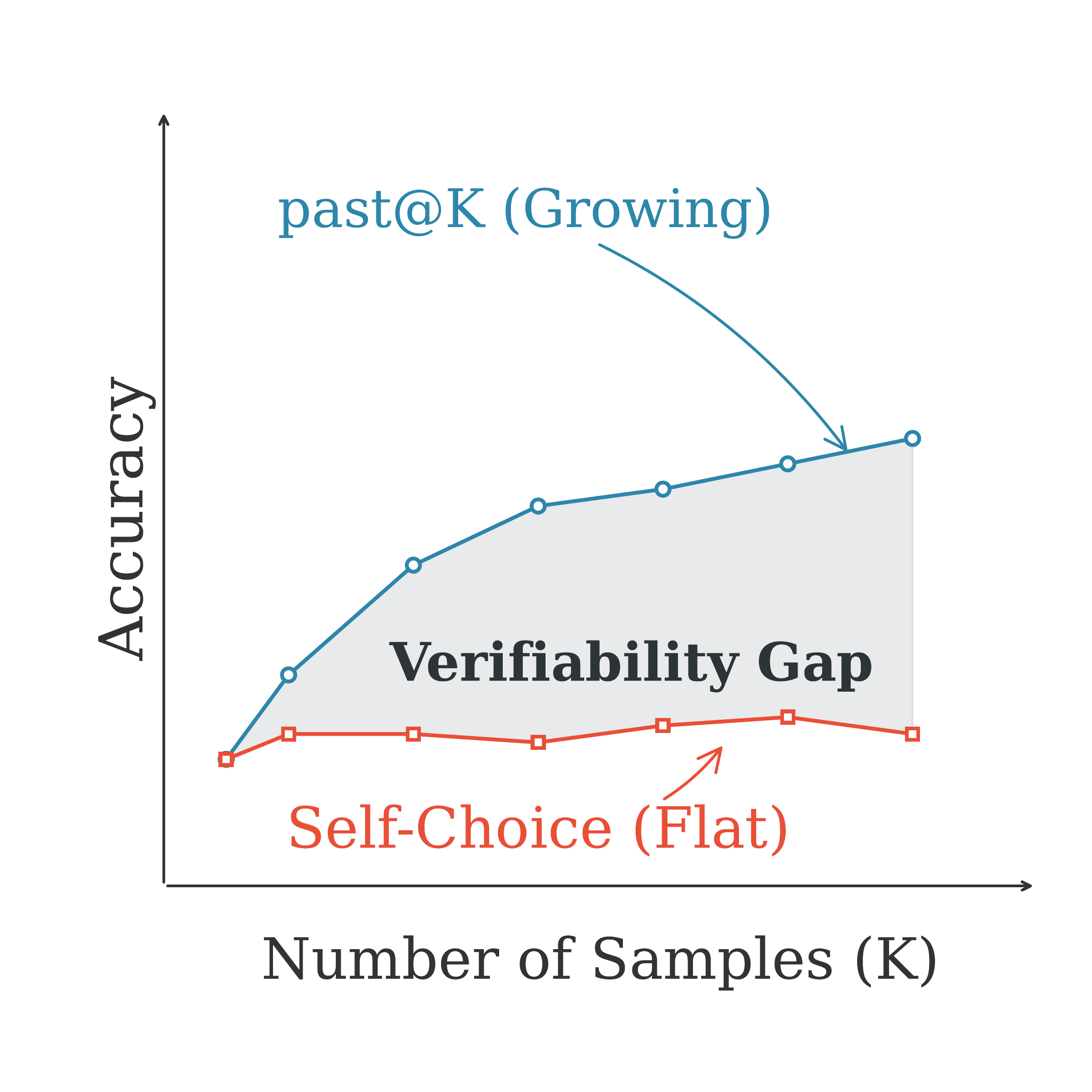
Parallel scaling samples multiple independent trajectories, expanding the solution space. While pass@K increases monotonically, the self-choice accuracy—where agents must identify the correct solution from their own generations—consistently lags behind.
This verification gap limits practical utility: agents can generate correct answers but fail to reliably select them. Even using GPT-5 as an external verifier does not close the gap.
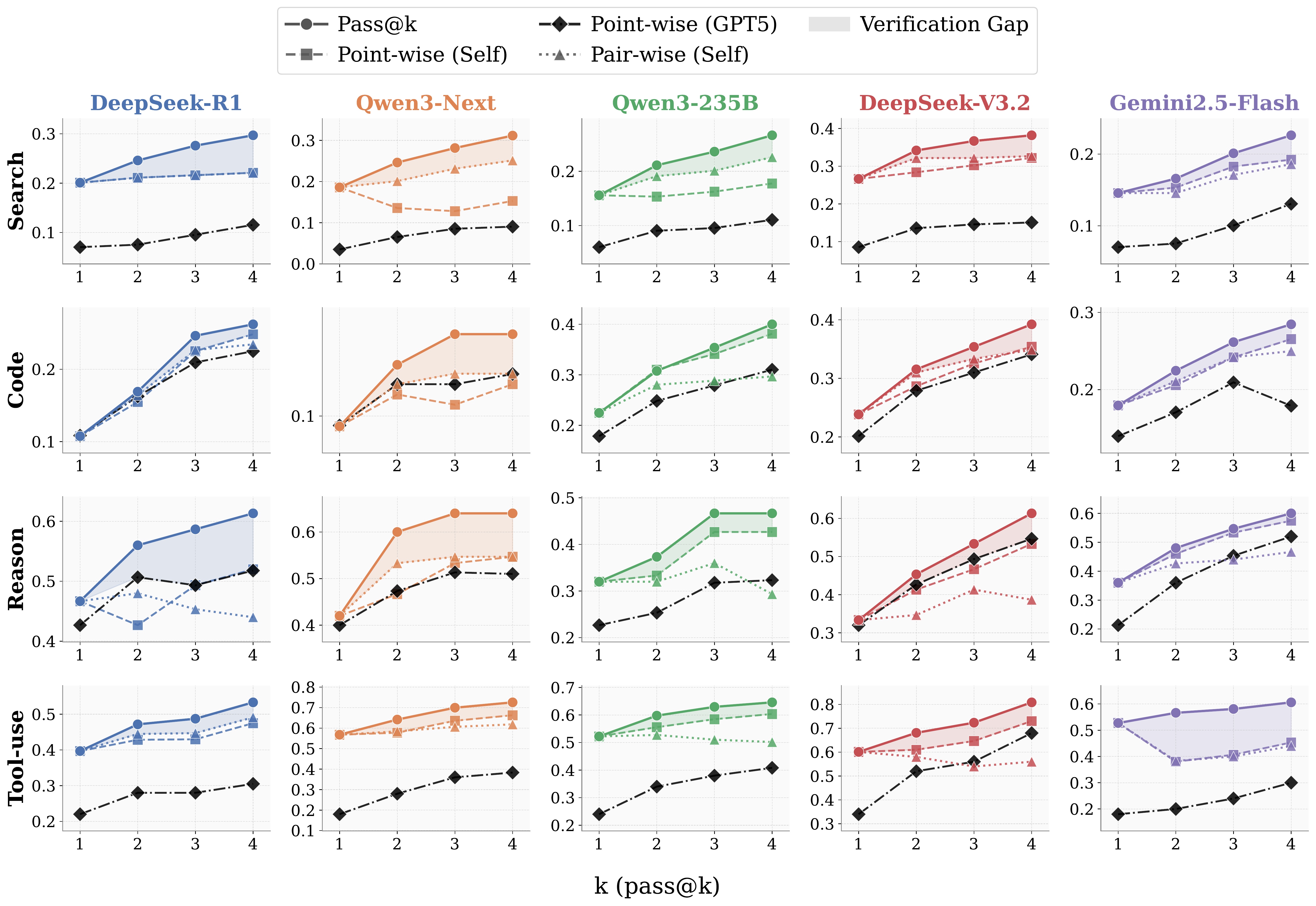
Verification gap between generation and self-choice. The dashed and dotted curves represent two self-choice strategies, while the diamond denotes a stronger evaluator, GPT-5.
Coming soon.